

Table Of Content
- Data Journey
- History
- What is Agile Development and how does it work with data analytics?
- What is data analytics, and how does it relate to lean manufacturing?
- What is DevOps?
- Isn’t DataOps just DevOps for Data?
- What problem is DataOps trying to solve?
- DataOps organization.
- How do you prove that DataOps is really adding value?
- The DataOps Automation: What Is It?
DataOps encompasses a range of technical methods, operational workflows, cultural standards, and architectural frameworks that facilitate:
1. Swift innovation and experimentation, delivering fresh insights to consumers at an accelerated pace.
2. Exceptionally high data precision and minimal error rates.
3. Collaboration across intricate networks of individuals, technologies, and environments.
4. Transparent measurement, monitoring, and communication of outcomes.
To truly grasp DataOps, it’s essential to delve into its intellectual lineage, identify the issues it aims to address, and illustrate it with a real-world example of a DataOps team or entity. Our exploration begins with a broad conceptual overview before delving into pragmatic and actionable insights, as this approach best aids data professionals in comprehending the potential advantages of embracing DataOps.
Data Journey
The Data Journey serves as the initial step toward instilling DataOps practices within your organization. The concept revolves around prioritising comprehension and observation of the data’s journey within your production environment, tracing its path from ingestion through processing to delivering actionable insights. This monitoring endeavour pinpoints data discrepancies, tool malfunctions, and timing discrepancies, facilitating swift victories for your DataOps implementation by fostering immediate enhancements. Minimizing production errors bolsters data reliability and gives your team more bandwidth to concentrate on automation efforts. Crucially, these advancements unfold within a matter of days, not months. The framework hinges on just five pillars, streamlining the process for teams to swiftly garner value with minimal effort and without substantial alterations to existing production setups.
Refer Data Journey Manifesto https://datajourneymanifesto.org/
History
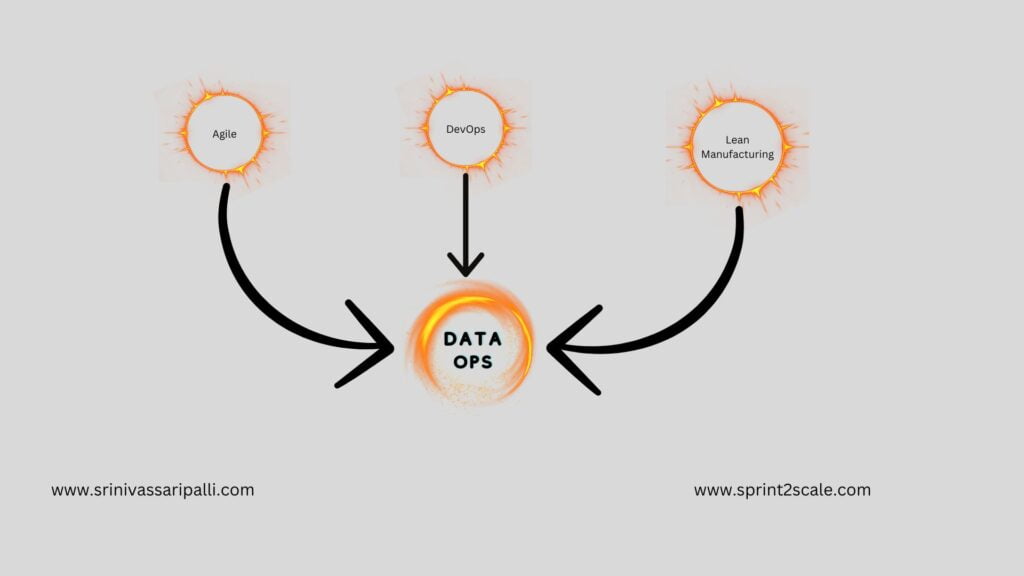
The roots of DataOps can be traced back to the groundbreaking contributions of management consultant W. Edwards Deming, whose work is often heralded for catalysing the post-World War II economic revival in Japan. The manufacturing methodologies championed by Deming have since found resonance in realms beyond manufacturing, including software development and IT. DataOps extends these methodologies into the domain of data management. Essentially, DataOps applies principles from Agile development, DevOps, and lean manufacturing to the realm of data analytics development and operations. Agile, for instance, draws upon the Theory of Constraints, advocating for smaller batch sizes to reduce work-in-progress and enhance overall system throughput in software development. DevOps naturally emerges when lean principles like waste elimination, continuous improvement, and holistic focus are applied to application development and delivery processes. Furthermore, lean manufacturing places a steadfast emphasis on quality, leveraging tools such as statistical process control to optimise data analytics operations.
What is Agile Development and how does it work with data analytics?
For DataOps to achieve effectiveness, it must prioritize collaboration and innovation. To facilitate this, DataOps integrates Agile Development into data analytics workflows, fostering improved efficiency and effectiveness through enhanced teamwork between data teams and users. Within Agile Development, the data team releases new or updated analytics in brief increments known as “sprints.” These short cycles of innovation allow the team to continually reassess priorities and readily adapt to evolving requirements, driven by continuous feedback from users. Such responsiveness is unattainable under the rigid constraints of Waterfall project management, which confines teams to lengthy development cycles, detached from user input, culminating in a single “big-bang” deliverable.
Research demonstrates that projects are completed more swiftly and with fewer defects when Agile Development supplants the traditional Waterfall sequential approach. Agile methodology proves particularly advantageous in environments marked by rapidly evolving requirements—a common scenario within the realm of data analytics. Within a DataOps framework, Agile methods empower organizations to swiftly address customer needs and expedite the delivery of value.
Related Read: Five biggest obstacles in Agile
What is data analytics, and how does it relate to lean manufacturing?
Originating in the Japanese manufacturing sector (e.g., Toyota), lean manufacturing is a practice that prioritizes reducing waste without compromising efficiency. Data analytics also controls and orchestrates a data pipeline, in contrast to Agile and DevOps, which are concerned with analytics deployment and development. Reports, models, and views are the outputs of the data that continuously enters the pipeline from one side. One aspect of data analytics that pertains to “operations” is the data pipeline. A good way to think about the data pipeline is as a production line where quality, efficiency, restrictions, and uptime are all closely monitored. We refer to this pipeline as the “data factory” in order to completely embrace this industrial mindset.
Data flow across operations is a key area of concentration in DataOps. In data operations, the data factory is orchestrated, monitored, and managed. The statistical process control (SPC) method is an effective lean manufacturing tool. Statistical Process Control (SPC) checks that the data pipeline’s operational and data characteristics are within acceptable ranges of statistical variation. When applied to data analytics, SPC leads to significant benefits in efficiency, quality, and transparency. Implementing SPC ensures that the data analytics pipeline verifies the data as it flows through the operational system. The data analytics group will be the first to know about any irregularities thanks to an automated notification system.
The term “DataOps” suggests that it draws mostly from DevOps, but in reality, DataOps’s philosophical foundation is a combination of Agile, DevOps, “lean,” and statistical process control. SPC coordinates, monitors, and verifies the data factory, while Agile manages the creation of analytics and DevOps optimizes code verification, builds, and delivery of new analytics. Agile, DevOps, and statistical process management form the basis of DataOps.
What is DevOps?
DevOps is a methodology for creating software that uses automation to speed up the build process, which was previously called release engineering. Automating code integration, testing, and deployment is at the heart of DevOps, which aims to facilitate continuous software distribution through the use of on-demand IT resources. Software development (“dev”) and information technology operations (“ops”) are becoming more integrated, which speeds up deployment, cuts down on time to market, reduces defect rates, and speeds up problem resolution.
The software release cycle time for top firms has been cut in half, from months to seconds, all thanks to DevOps. They were able to expand and take the lead in rapidly developing markets because of this innovation. Numerous software releases occur daily at companies such as Google, Amazon, and many more. These businesses owe a great deal of their success to DevOps, which has greatly improved the speed and quality of code releases.
Isn’t DataOps just DevOps for Data?
When the word DataOps is first heard, almost everyone assumes this. The name “DataOps” is a bit deceptive from a semantics standpoint, but it does convey the idea that data analytics can accomplish what DevOps did for software development. So, when data teams use new tools and processes, DataOps can improve quality and cycle time by an order of magnitude. The software development pipeline is optimized using DevOps. Companies like Google, Amazon, and Netflix are able to release millions of lines of code annually because of this. DataOps is responsible for managing a dynamic manufacturing operation while also speeding up software development, specifically new analytics. DataOps encompasses DevOps and other approaches that are relevant to the specific difficulties of overseeing a pipeline of data operations that is vital to a company.
What problem is DataOps trying to solve?
When you implement DataOps, you take command of your workflow and processes, removing all the roadblocks that are holding your data organization back from reaching its full potential. The time it takes to get from an idea’s inception to the release of final analytics is known as “cycle time.” Prolonged processing times deter and disappoint users while stifling innovation.
Data teams should be as efficient as a well-oiled machine, always soliciting and acting upon user suggestions for improved models and analytics through rapid iteration. Regrettably, we have found the exact reverse to be true. Data and analytics mistakes disrupt data teams all the time. The majority of data scientists devote their time to manually processing and manipulating data. Everybody on the data team, including stakeholders, hates it when development is sluggish and full of mistakes. There are several causes of lengthy analytics cycle time:
- Missing collaboration across data team members
- Discord within the data organization’s departments
- While we wait for IT to configure or dispose of system resources
- Patiently awaiting data availability
- Proceeding with caution and slowness to prevent subpar results
- Subject to necessary clearances, such as those of an Impact Review Board
- Data structures that are never changed
- Obstacles in the process
- Backlog of technical debt from earlier releases
- The work is unanticipated and of low quality.
DataOps organization.
For the reasons stated before, DataOps does not refer to a single entity. Here we will go over several examples of companies that help you understand DataOps.
Data lakes automate the consolidation, transformation, and presentation of tens or hundreds of sources of data to end users through analytics graphs and charts. Data inputs, outputs, and business logic at each stage of transformation are validated by automated tests, which are statistical process controls. The data team will receive real-time status, warning, and failure signals from each of these process controls. Additionally, in the event of a catastrophic error, the tests employ a virtual Andon cord to halt the data source. There is almost no room for processing errors in the data analytics pipeline, and data problems are detected mid-pipeline, preventing analytics from being corrupted. The data pipeline’s quality and uptime KPPs (key performance metrics) increase dramatically, surpassing goals. Errors cause less than 1% of the effort to go unplanned. Every bit of wasted manual labor that was previously used to run, check, and repair the data pipeline is now being redirected to tasks that generate more value. No longer can the data organization depend on miracles and wishful thinking.
The workflow and method for creating new analytics are now much more efficient and run well. By abstracting and replicating the target operations environment in virtual workspaces, it is possible to improve test accuracy, repeatability, and analytics portability. The objective is to reduce the cycle time from months to hours or days.
To improve and facilitate communication and coordination within a team and between groups in the data organization, DataOps leverages process and workflow automation. By reorganizing data analytics pipelines as services, also referred to as microservices, one can create a robust, open, effective, and repeatable analytics process that integrates all development and operations workflows. It lets groups work autonomously according to the iteration cycle that works for their toolchain, and then, with little human intervention, merges all of their work into a cohesive whole ready to be delivered to clients.
How do you prove that DataOps is really adding value?
Assessing a number of crucial metrics and results that show DataOps’ influence on an organization’s data operations and overall business objectives is necessary to prove the value it adds. Here are some ways to prove the value of DataOps:
1. Time to Market: Measure the time it takes to develop and deploy data-driven solutions from ideation to production. DataOps aims to streamline processes, reduce bottlenecks, and accelerate the delivery of data products and insights. A decrease in time to market indicates the effectiveness of DataOps in improving efficiency and agility.
2. Quality and Accuracy: Evaluate the quality and accuracy of data products and analytics delivered through DataOps practices. This can be assessed by comparing the accuracy of insights generated before and after implementing DataOps methodologies. A reduction in errors, discrepancies, and inaccuracies demonstrates the value of DataOps in enhancing data quality and reliability.
3. Resource Utilization: Analyze resource utilization, including human resources, infrastructure, and tools, before and after implementing DataOps. Improved resource efficiency, such as reduced idle time, optimized utilization of data infrastructure, and better allocation of talent, indicates the effectiveness of DataOps in maximizing resource ROI.
4. Operational Efficiency: Assess the efficiency of data operations processes, such as data ingestion, preparation, transformation, and deployment. Metrics like cycle time, throughput, and productivity can be used to measure operational efficiency improvements achieved through DataOps practices. The value that DataOps adds by streamlining operations is evident in increased throughput, shorter cycle times, and higher productivity.
5. Business Impact: Evaluate the impact of data-driven insights and solutions on business outcomes and key performance indicators (KPIs). This may include metrics like revenue growth, cost savings, customer satisfaction, market share, and competitive advantage. Demonstrating a positive correlation between data-driven initiatives enabled by DataOps and tangible business results confirms its value in driving business impact.
6. Customer Satisfaction: Solicit feedback from internal stakeholders, data users, and customers regarding the usability, relevance, and effectiveness of data products and insights delivered through DataOps practices. Positive feedback, increased user satisfaction, and alignment with customer needs indicate the value of DataOps in meeting user expectations and driving customer success.
By analyzing these metrics and outcomes, organisations can effectively demonstrate the value added by DataOps in improving data operations, driving business impact, and enhancing overall organisational performance.
The DataOps Automation: What Is It?
An organization’s current toolchain needs to be supplemented with new approaches and automation in order to apply DataOps. Adopting a pre-built DataOps platform is the quickest approach to reaping the benefits of DataOps; however, other businesses choose to build their own capabilities from the ground up. The DataOps unification of the workflow and processes pertaining to data analytics strategy, development, and operations as a whole improves teamwork. It makes use of your current tools and integrates them into orchestrations that generate analytics and turn raw data into insights automatically. By overseeing the development, implementation, and production execution of analytics, DataOps Automation achieves this objective. There are four main features available in the DataOps Automation software that are available on the market:
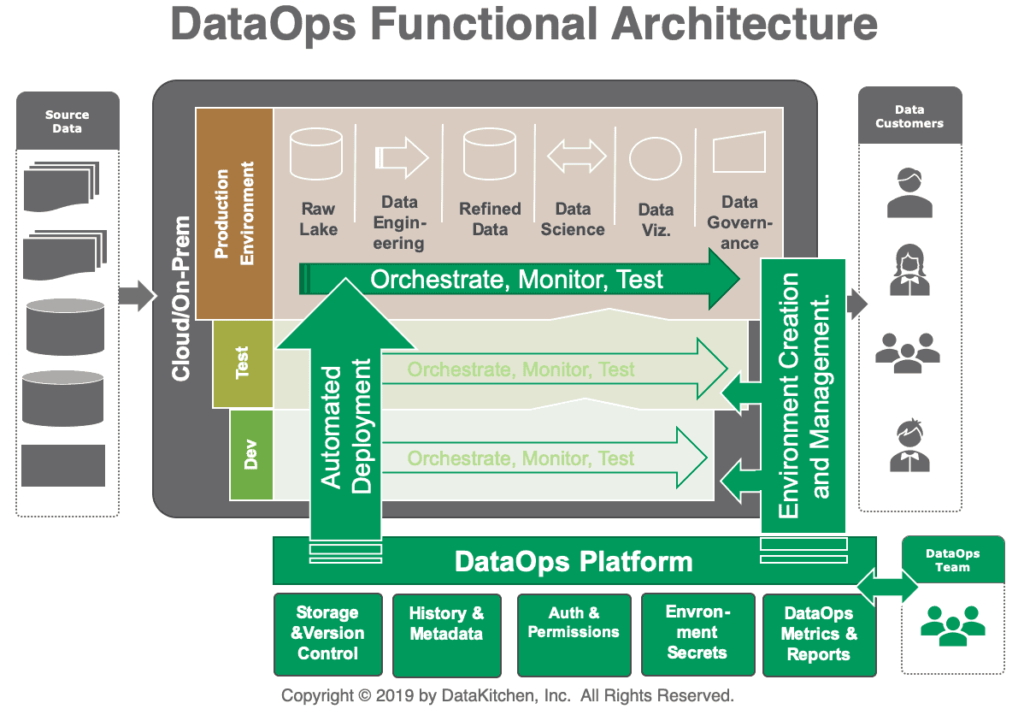
Picture Credit: datakitchen
By utilizing virtualization, DataOps creates secure and synchronized workspaces by isolating your development and production environments. Mistakes during deployment can be prevented by bringing the two technical environments into alignment. Workspaces and domains are both protected by access control. Data scientists may quickly and easily set up self-service development sandboxes that have all the necessary resources for a new project, including test data, validation tests, tools, and a password vault. End the months-long wait for IT.
Deploys automatically – With only a few clicks, new analytics can go from development to production engineering and finally operations after passing rigorous validation tests. Reducing deployment time and effort, verification tests take the place of your impact review board.
Coordinates, validates, and keeps tabs on the data pipeline – Analytics begin with data flowing in from hundreds or thousands of sources and continues with integration, cleaning, processing, and publication. Distributed tests in the data pipeline keep an eye on ongoing tasks and look for unusual data as millions of points of data flow through it. Almost no mistakes make it to user analytics. Warnings, alerts, or even data source suspension may be triggered by DataOps depending on the seriousness of the problems detected. Operations and development can now be seen in a whole new light thanks to dashboards that summarize test results and activities. To help you track the success of your DataOps project, the tools automates the process and generates metrics for quality and productivity.
Promotes teamwork by automating workflows for better task coordination and DataOps fosters collaboration. Analytics may be more easily transferred from one person to another and into production with the help of workspace environments, which provide a framework for the development workflow. Analytics components in sandboxes can be reused, which helps save time and ensures consistency. Collaborating with source control, workspaces provide for centralized control of artifacts through branching and merging. Everybody can see the big picture of the operations and development processes using a right DataOps tool stacks.
DataOps Automation platforms streamlines development processes, automates pipelines for data operations, and implements quality controls to reduce the amount of unplanned work. A more open and strong workflow is the result of team and group task collaboration. Almost all data mistakes are eliminated with DataOps tests. Faster analytics development and deployment, user delight, and insights that significantly affect the enterprise’s goals and initiatives are all possible with the right tool stack.





No Comment! Be the first one.